In the age of information, the sheer volume and complexity of data have given rise to the concept of Big Data. Managing and extracting meaningful insights from this vast sea of information presents unique challenges, and solutions like Hadoop have emerged as key players in this data revolution.
The Evolution of Big Data
As we generate more data than ever before, traditional data processing systems struggle to keep up. The evolution of Big Data signifies a paradigm shift, where organizations recognize the potential value of large datasets in making informed decisions and gaining competitive advantages.
Understanding the Big Data Challenge
Big Data is characterized by the three Vs: Volume, Velocity, and Variety. The challenge lies in processing and analyzing massive amounts of data, often in real-time, and dealing with diverse data types.
Introducing Hadoop: A Solution to Big Data Challenges
Hadoop, an open-source framework, is designed to tackle the challenges posed by Big Data. Its distributed computing model allows for parallel processing across clusters, enabling the efficient handling of large datasets.
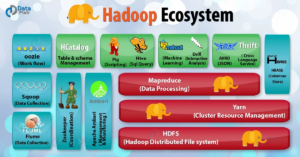
Core Components of Hadoop
Hadoop Distributed File System (HDFS)
HDFS divides data into smaller blocks, distributes them across a cluster, and ensures fault tolerance through data replication.
MapReduce: The Processing Engine
MapReduce is Hadoop’s programming model for processing and generating large datasets. It divides tasks into mappers and reducers for parallel processing.
YARN: Resource Management
YARN manages resources, allowing multiple applications to share cluster resources efficiently.
Hadoop Ecosystem
Hadoop’s ecosystem extends beyond its core components, offering a variety of tools and frameworks for specific data processing tasks. Components like Hive, Pig, and HBase complement Hadoop’s capabilities.
Beyond MapReduce: Spark and More
Apache Spark, a fast and versatile data processing engine, enhances Hadoop’s capabilities by providing in-memory data processing and machine learning functionalities.
Real-world Applications
Hadoop’s impact extends to various industries. Real-world applications include predictive analytics in finance, personalized recommendations in e-commerce, and data-driven healthcare solutions.
Transforming Industries with Big Data and Hadoop
Industries are undergoing transformative changes as they harness Big Data and Hadoop. From improving customer experiences to optimizing supply chains, organizations are leveraging data for strategic decision-making.
Challenges and Solutions
While Hadoop addresses many Big Data challenges, it also faces obstacles, including data security and complexity. Ongoing advancements in technology continue to provide solutions to these challenges.
Future Trends in Big Data and Hadoop
The future of Big Data and Hadoop is promising. Trends include the integration of machine learning, the rise of edge computing, and continuous innovations in data processing technologies.
Conclusion
In conclusion, Big Data and Hadoop represent a revolutionary force in data management. As we navigate the complexities of vast datasets, Hadoop continues to play a pivotal role in enabling organizations to turn data into actionable insights, driving innovation and shaping the future of data-driven decision-making
FAQs
- How does Hadoop address the challenges posed by Big Data?
- Hadoop’s distributed computing model allows for parallel processing across clusters, enabling the efficient handling of large datasets.
- What are the three Vs characterizing Big Data?
- Big Data is characterized by Volume (large amounts of data), Velocity (high speed at which data is generated), and Variety (diverse types of data).
- What is the role of Apache Spark in enhancing Hadoop’s capabilities?
- Apache Spark provides in-memory data processing and machine learning functionalities, complementing Hadoop and enhancing its speed and efficiency.
- Can you provide examples of real-world applications of Big Data and Hadoop?
- Real-world applications include predictive analytics in finance, personalized recommendations in e-commerce, and data-driven solutions in healthcare.
- What challenges does Hadoop face, and how are they addressed?
- Hadoop faces challenges such as data security and complexity. Ongoing advancements in technology provide solutions to these challenges, ensuring the continued relevance of Hadoop in the evolving data landscape.